

When it comes to web hosting performance, numbers usually speak for themselves. But behind those numbers, there are decisions, investments, and above all, a lot of work. Today, we’re proud to announce that all our clients are now benefiting from a major improvement in the speed and responsiveness of their hosting — at no additional cost.
Yes, you read that correctly: No settings to change. No plans to upgrade. No extra fees.
Next-Generation Servers = Real-World Results

Last May, we invested in a brand-new fleet of servers for our data centre. Each machine is equipped with two AMD EPYC 9475F processors, known for their raw computing power and remarkable energy efficiency. Internally, we like to call them performance monsters — and we’re not exaggerating.
So, what does this mean for your website?
On average, a single core from these new processors delivers up to 6.5x more performance than a core from our previous generation of servers. And this improvement is noticeable in everyday use:
| Usage | Typical Performance Gain |
|---|---|
| WordPress page loading | 50% to 80% faster |
| Complex WooCommerce pages (checkout, filters, dynamic catalogues) | 2–3× faster |
| Common SQL queries (posts, pages, metadata) | 2–4× faster |
| Advanced WooCommerce database operations | 2–5× faster |
| Reports, exports, non-optimized analytics | 3–8× faster |
In other words:
✅ Pages load faster
✅ Online stores feel more responsive
✅ WordPress dashboards open more quickly
✅ Heavy operations (reports, filters, dynamic calculations) run smoothly
You didn’t have to do anything. Your website is simply faster.
But… the road to get here wasn’t simple.
Our goal from the start was clear: Upgrade the infrastructure with zero impact on websites, email, or operations. And for a while, that’s exactly how things went. A few servers migrated, happy clients, no downtime — the perfect scenario… until the problems appeared.
Issue #1 — Network Cards That “Forgot” to Transfer Traffic
At first, everything looked normal. But we soon noticed behaviour that simply doesn’t belong in a data centre: the new generation of Intel network cards would completely drop the connection — even under perfectly normal load.
- Not a small packet loss.
- Not temporary latency.
- A total network link loss.
To restore connectivity, the network interface had to be manually reset — which is obviously unacceptable on a production server. This was the kind of issue that never appears in lab testing — only when real clients are using the system continuously.
We tried everything:
- Firmware and microcode updates
- Alternate driver versions
- Network queue tuning
- Full reinstallations
- Cross-environment comparison tests
- Diagnostics with Dell and Intel technicians

The issue persisted. After thorough testing, it became clear that the hardware itself was the root cause. The only reliable and professional fix was to replace the network cards with a proven, stable model designed for sustained high-load performance.
This required significant time and hardware investment — but it was necessary to maintain our reliability standards.
And an interesting note:
Intel still has not fixed this issue on that card series. We’re very glad we acted early.
Issue #2 — Servers Slowing Down Mysteriously… Every 24 Hours
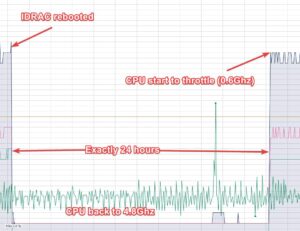
This one was even trickier. It wasn’t gradual slowdown, overload, or real overheating.
It was triggered by — of all things — the server firmware.
Every ~24 hours, Dell’s internal management firmware would perform a routine check on one of the power supplies (PSUs). This check triggered a false thermal alert.
In other words:
The firmware thought the server was overheating — even though CPU temperatures were perfectly normal. When a server believes it’s overheating, it does the only responsible thing: It instantly throttles performance to protect itself.
Result: within a split second, CPU performance dropped by up to 88%.
- No crash
- No visible error
- Just… a server suddenly running far too slowly
Diagnosing this required ruling out every possibility:
- Actual CPU temperatures
- RAM and VRM heat
- Power supply health
- Thermal management logic
- CPU scheduling
- BIOS power states
- Kernel behaviour
- And more!
After months of cross-analysis, monitoring, and isolated testing, we were able to reproduce the issue and present undeniable evidence to Dell.
Once submitted, Dell acknowledged the firmware fault and released a corrective update. After applying it, the issue disappeared immediately and permanently.
Conclusion — What This Means for You
This infrastructure upgrade represents a significant investment — one made for a single purpose: To deliver faster, more stable, and more responsive hosting services. Today, every one of our clients benefits from improved performance without any action required on their part. No costs. No configuration changes. Just a better experience.
This project required patience, precision, and many hours of diagnostics and collaboration. But the outcome is worth it. We remain committed to our mission: To provide fast, stable, secure web hosting with service that feels like 5-star hospitality.
And we’re not done yet.
More improvements are on the way. 😉
Leave a Reply